Parsing CSS for EPUB
December 26, 2011
New York, N.Y.
I've been trying to build an EPUB viewer for Windows 8, mostly because I want to read books on the Windows 8 tablet I got at the Build conference, and it's more fun writing one's own application rather than using someone else's. This will obviously not be a commercial product or I would have thought of a snappier and less wonky name for the program than The New Epublic! [I've decided I don't want to distribute the code at this time. — Jan. 5, 2012]
This installment of the program doesn't display books any better than the previous version, but I have made a great deal of progress in parsing the CSS files that comprise an essential part of EPUB packages. The solution now consists of one application project (TheNewEpublic) and five library projects, which are listed here with their full names but which I often shorten in my mind to the nickname show in quotes:
- Petzold.Epub.Viewer.Windows8 ("Viewer")
- Petzold.Epub ("Epub")
- Petzold.Epub.Common ("Common")
- Petzold.Epub.Html ("Html")
- Petzold.Epub.Css ("Css")
The dependencies are shown here:
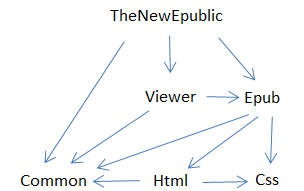
It's quite possible that the last four of these will eventually be merged into a single library, which will be a platform-independent library for parsing and processing EPUB files, and that this library will be accessed only through the device-dependent viewer (Petzold.Epub.Viewer.Windows8 in this case). But for now, this organization is convenient for separating functionality.
An EPUB is basically a ZIP package containing some EPUB-specific XML files plus HTML files, CSS files, image files (sometimes), and font files (sometimes). The HTML files are actually XHTML files, so they are easily parsed with tools such as the .NET XmlReader. But CSS is a whole other story, and parsing the CSS files is probably one of the biggest jobs in constructing an EPUB viewer. Needless to say, it's also a vitally essential part, because CSS provides virtually all the formatting information for constructing pages from the HTML files.
There are various ways to count the number of properties that CSS 2 supports. Appendix F of the CSS 2 specification provides a table listing all the properties, and this table has about 100 rows. Not all of these properties are supported in EPUB documents however. The property list in Section 3.3 of the EPUB Open Publication Structure 2.0.1 specification restricts itself to about 65 of these properties, and if you eliminate all the properties related to audio (which I am), you're down to about 50.
But it's not just the properties that makes CSS complex. It's the various values of these properties that gets really hairy. For example, the CSS font-size can have absolute values (small, medium, large, etc), relative values (smaller, larger), lengths (such as 16px or 1.5em), percentages, or the value inherit. The various values of the various CSS properties must be encapsulated in specialized types. That's part of the reason why the Petzold.Epub.Css library contains over 50 classes and structures.
Some background:
CSS stylesheets can be referenced from HTML files in several ways. The most common (at least in EPUBs) is through a link element in the head section. A stylesheet can also be embedded directly in the HTML file with a style element, also in the head section. It's also possible for a CSS file to be referenced via an xml-stylesheet processing instruction as documented here, but I've never seen one in an EPUB, and I currently don't handle those. A stylesheet can contain @import rules that reference other style sheets, although I've never seen these in EPUB files either. A stylesheet can also appear in a @media rule. Every HTML document should also begin with a default stylesheet, and the CSS 2 specification conveniently defines one.
All the stylesheets that apply to a particular HTML document and a particular media type (in the case of the @media rule) should basically be merged into one stylesheet for convenience in determining what set of styles apply to a particular element in that document. The parsing and merging of stylesheets occurs in a class in the Petzold.Epub.Css library called StyleSheet.
A stylesheet typically contains statements that look something like this:
h1, h2 { font-weight: bolder; text-align: center }
The h1 and h2 at the left are called "selectors." What follows is a block of properties where each property (font-weight and text-align) is followed by a colon and the value of that property. These are separated by semicolons. In the Petzold.Epub.Css library, a collection of properties and their values is the abstract class PropertyBlock and two derived classes: StyleSheetPropertyBlock and PageRulePropertyBlock. The latter applies to properties defined in @page rules.
A peak inside StyleSheetPropertyBlock will reveal a big part of the overall processing of these properties and values. The class consists of a bunch of properties corresponding to the CSS properties. Here's a sample:
public FontFamily FontFamily { protected set; get; }
public FontStyle FontStyle { protected set; get; }
public FontVariant FontVariant { protected set; get; }
public FontWeight FontWeight { protected set; get; }
public FontSize FontSize { protected set; get; }
All these types — FontFamily, FontStyle, and so forth — are structures defined in the Types directory of the Petzold.Epub.Css library. They are structures to make the cloning of PropertyBlock objects easier. For the little CSS statement shown above, you don't want the same PropertyBlock object to be stored for both h1 and h2 because other statements in the stylesheet could apply to h1 only or h2 only. You'll want separate PropertyBlock objects but it's faster to clone the object than to reparse the properties for each element they apply to.
The properties defied in StyleSheetPropertyBlock are set in a massive switch statement:
protected override void ParsePropertyValue(string property, string value)
{
switch (property)
{
...
case "font-family":
this.FontFamily = new FontFamily(value, true);
break;
case "font-style":
this.FontStyle = new FontStyle(value, true);
break;
case "font-variant":
this.FontVariant = new FontVariant(value, true);
break;
case "font-weight":
this.FontWeight = new FontWeight(value, true);
break;
case "font-size":
this.FontSize = new FontSize(value, true);
break;
case "font":
Font font = new Font(value);
this.FontStyle = font.Style;
this.FontVariant = font.Variant;
this.FontWeight = font.Weight;
this.FontSize = font.Size;
this.LineHeight = font.LineHeight;
this.FontFamily = font.Family;
break;
...
default:
System.Diagnostics.Debug.WriteLine("PropertyBlock not handling property {0} = {1}", property, value);
break;
}
}
All these type structures perform their own parsing of the property values. The second argument indicates if this particular property is defined as inherited through the element tree. Notice the Font class used as a shortcut to set several properties in one string. Because stylesheets can be merged, the PropertyBlock class has its own cloning and merging logic. A property block can also appear in an HTML element itself in a Style attribute.
Selectors are sometimes simple, such as h1 or p or * referring to all elements. But they can also be quite complex. You can specify properties for elements that have a particular ID, or a particular class name, or attribute values, or which have a child or descendent or sibling relationship to other elements in the document tree. Here's one in a stylesheet from a book downloaded from the epubBooks web site:
#epb-frontpage p strong { font-size: 1em; }
That selector can be translated as "Any strong element that is a descendent of a p element that is a descendent of any element with an id value of "epb-frontpage". These various combinations are handled in the SimpleSelector and Selector classes. A SimpleSelector encapsulates a single element in the selector, and the Selector is basically a List of SimpleSelector objects. For a particular element, all the selectors for that element are taken into account, but ordered based on a "specificity" score documented here. That's part of the "cascade" of Cascading Style Sheets.
Within the Stylesheet class, the selectors and their properties are stored in an array of Dictionary objects:
public IDictionary<Selector, PropertyBlock>[] PropertyBlocks
{ protected set; get; }
The array index indicates an element type. It's the integer representation of the HtmlElementType enumeration, which is 0 for all elements (*), 1 for a, 2 for abbr, 3 for acronym, and so forth. These are all the HTML elements supported in EPUBs that are documented here. Each element can be associated with a bunch of different Selector objects, which are keys to the dictionary.
A stylesheet in an EPUB can also contain "at-rules" which are keywords preceded by the at (@) sign. The biggie is @page, which indicates the margins for the pages of the book. An EPUB stylesheet can also contain @import for referencing other stylesheets and @media for a stylesheets that applies to specific media types, such as print. I haven't seen an @import rule yet, but there's a @media rule in the default stylesheet in the CSS 2 specification I referenced above.
Another important at-rule is @font-face. You probably won't find this in public domain EPUBs, but it's pretty much standard in commercial EPUBs. This is how font files embedded in the EPUB package are referenced. The @font-face rule contains a description of a font in terms of font families, styles, weights, etc, and then a src that indicates the file name of the font file that applies to that font description.
The @font-face rule gave me a lot of trouble. One issue is that it's not actually part of the CSS 2 specification! It only seems to be documented in a 1998 draft CSS 2 specification. Fortunately, EPUB only supports a subset of these properties, as discussed here. Although I originally thought I'd use a PropertyBlock derivative for these properties, I realized I couldn't. The font-style property in a @font-face rule is rather different than the regular font-style property in a stylesheet, mostly because the @font-face version can have multiple styles, and the particular font file applies to all of those styles. I eventually created a bunch of specialized properties for @font-face rules, which are in the Rules directory of Petzold.Epub.Css, and have the word Descriptor in their names.
What makes parsing the CSS more complex is the presence of strings in a stylesheet. These strings can contain crucial characters such as commas (used for separating selectors), semicolons (used for separating properties in a block), colons (used to separate properties from their values), and curly brackets (used for delimiting blocks). The possible presence of these characters in strings makes it impossible to use common String methods such as IndexOf and Split because these methods won't recognize that characters in strings should be ignored. This meant that I had to provide my own versions of a lot of these methods in a static class called CssParsingHelper, and I know I still need to go through a few of my classes (particularly Selector and SimpleSelector) and make sure I'm not using the String methods in a dangerous way.
Of course it's always nice if you can assume that the files you're parsing are free of errors. But error-free files are not actually required by the CSS 2 specification! The specification contains a whole section on rules for handling parsing errors, and I'm pretty sure I'm not handling all of these correctly.
Still, I've made a great deal of progress, and I believe that what remains in the CSS parsing work is merely detail. With the sample EPUB books I'm working with, my CSS parsing doesn't raise any exceptions, and it logs unknown items with simple Debug.WriteLine calls.
Very soon after I began the coding to parse CSS files I realized that one of the most difficult jobs would be checking to see if I was doing it correctly. I decided to build this facility into the actual EPUB viewer. If you run the program and page through the unformatted text of a book. Here's the type of thing you'll normally see (reproduced half size from the Samsung tablets distributed at Build, but click for full size):

This is E. M. Forster's novel from the epubBooks web site. As you can see, the unformatted text looks just the same as it did three weeks ago. But now sweep your finger up from bottom or down from the top to display the application bar:

If you select "HTML" you'll get a three-paneled display with the left panel listing all the HTML files in the EPUB package. Select one and you'll see the raw HTML file in the center panel and the parsed HTML in the right panel:

Both the raw HTML and the parsed HTML are displayed in read-only TextBox elements. The TextBox for the raw HTML wraps lines; the parsed HTML does not but provides horizontal scrolling. For the parsed HTML, the indentation shows the tree structure. Each bullet is followed by an element name, and then a list of the attributes and their values are listed.
Similarly, you can select "CSS" from the application bar and view all the CSS files in the EPUB package in a similar manner:

The display of parsed CSS at the right is ordered by element, then all the selectors for that element, with the specificity score, the properties and their values. The at-rules are at the end.
(Gosh, I'm just about to post this thing, and I see a discrepancy between the CSS file and the parsed result! Huh!)
Anyway, I am getting close to the point where I can actually begin applying these CSS properties to the HTML elements and format the text. I suspect I'll need additional types of displays to check if that logic is working correctly as well.